Novel Journeys
It’s been a little quiet lately, and for good reason: a new job in a new state. It’s been a bit hectic, but things are settled and I’m getting back to my personal projects.
I did get my first MongoDB and AngularJS app working before the chaos. I didn’t get much written down and my mini cluster has not been brought back to life from the move. I’ll have to decide whether to revive it or to just move on.
In the meantime, something a bit more mundane. I was getting a lot of lost packets at home, and I needed to figure out what was causing it. In the past I’ve just used Smokeping to give me a baseline for the network. I really didn’t feel like fussing with configurations and permissions. It is 2015 is it not? Surely I can just add a couple of IP’s into some kind of app and have it do everything for me.
I dusted off one of my machines from the cluster, installed CentOS 7 on it, and proceeded to install Zabbix. Zabbix has gotten a bit better; I only had to make one SELinux policy change to get it up and going. The navigation is still horrible though. After it took me way longer than it should, I plugged in a couple of IP’s and had some monitoring going. The only problem was that the values where getting rounded off. After the navigation frustration, I was starting to wonder if there was something easier. I looked for Docker container for Smokeping and sure enough, one existed.
Next, I looked for a UI for docker since my last few 10 minute forays into it didn’t bear a lot of fruit. I chose Cockpit, but I wasted a bit of time trying the CentOS version of Atomic Host. In my naiveness, I would say that it is not ready for playing with, or at the very least it does not have cockpit baked in. I installed the Fedora version of Atmoic Host, and I finally had something to work with.
1
| |
In the end though, I rarely used the interface, and this was all a lot easier without all of the side trips.
- Install a minimal version of CentOS 7.
- Install and start up libvirtd
1 2 3 | |
- Download the Fedora Atmoic host image to your /var/lib/libvirt/images/
Install the image. I used this guide.
You’ll need a
yum install genisoimagefor the authorizaion iso image. I also did install the extra storage for my instance, but I don’t know if it was strictly necessary. It was a little confusing but ROOT_SIZE is not for your docker storage, so you shouldn’t need to touch that.SSH to your atomic host
Install the docker container
$ sudo docker run --name smokeping -p 8000:80 -d dperson/smokepingAdd the IP’s that you want to monitor.
$ sudo docker exec smokeping smokeping.sh -t "<Group>;<Name>;<Hostname or IP>"An example:
$ sudo docker exec smokeping smokeping.sh -t "Local;LocalHost;localhost" $ sudo docker exec smokeping smokeping.sh -t "External;Level3_DNS;4.2.2.1"Do not put spaces in the name section. I did this the first time, and then I tried fixing it using the “docker cp” command, but apperently this version of docker doesn’t allow cp back into the container. In the end I wiped my config with a “docker exec smokeping smokeping.sh -w” and just used under scores.
Restart the container.
$ sudo docker restart smokepingEnjoy.
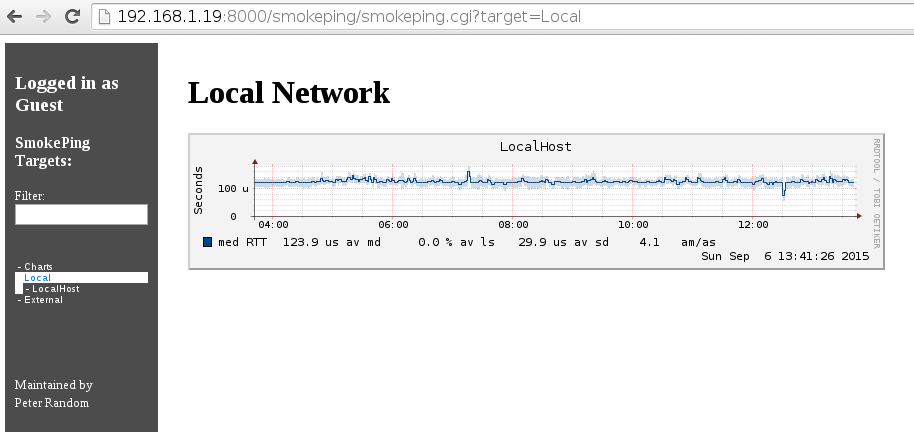
In the end it’s pretty simple once you have a docker host going as long as you avoided the side trips. Run a few commands, to configure your app, and off you go.
Importing
I wanted to try my hand at a MongoDB and AngularJS app. First things first, I wanted to find a dataset that would do MongoDB justice. The best thing that I came up with was Google’s wiki-links data set. Something big enough to not sit in RAM, but not to overwhelming, and something with a little bit of structure to it.
I made a simple parsing and importing script. I setup my MongoDB instances on my Eucalyptus cluster (that has very slow IO), and I’m using a 3 node replication setup. The dataset is split up into 10 files, each about 550M. Inserts where taking about 120s per 1000 records (safe inserts, and write majority). A few demotions, and we selected the master node to be the node on our Euclyptus cluster with the least contention. That got us down to about 95s per 1000 records. At this rate it was taking several days to import just 1 file in the dataset. I looked around and noticed that we weren’t really bottlenecked on CPU or IO, so I figured we could make the inserts in parallel and go a bit faster.
I’ve done the standard forking method in the past, so I wanted to try something new. I figured I would see what I could do with a message queue or something similar. I started with nanomsg, but the Perl bindings weren’t up to date with the latest beta (the beta just came out last month). I fussed with 0MQ for a bit, but when I started losing messages, I decided I could get lost down that rabbit hole pretty quick. Looking at a few benchmarks, I knew I was looking at either RabbitMQ or Qpid. After looking at some of the coding samples, I picked Qpid. It was in the distro repo’s and very easy to setup. It had examples in multiple languages including Perl. It had some easy to use command line tools for setting up queues, and even a script to do a quick performance test. On my workstation it was something like 200,000 messages a second with transient storage and 32,000 messages a second with persistent message storage. Easily enough that the queuing and dequeuing wasn’t going to be my bottleneck.
1 2 3 4 | |
I ripped apart my parser and inserter, and merged it with some of the example scripts, and now I have the parser queueing up records to be inserted, and an import for dequeuing and inserting into MongoDB. The parsing and queueing took about 2 minutes, and I have 5 copies of the importer script running each taking about 106s per 1000 records, with a bit more room to push it further.
As a side note, I should mention that I had to reboot my nodes in my Eucalyptus cluster, and I had lost my setup and data because I’m not using a block storage volume to store things in. So that prompted me to do a little bit more Ansible work, and now setup is a breeze. See my Ansible MongoDB playbook here. It needs a few tweaks to be better, but works for me at the moment.
Now time to finish up that AngularJS tutorial while these import.
A Jack, Fuzz, and Two Bits
A couple if miscellaneous updates while I’m in between a couple of projects.
Ansible
I started working up an Ansible playbook for installing my RSS reader. I got stalled as I filled the root partition in my Eucalyptus vm. So either recreate the image or get the playbook to install the supporting software on the ephemeral partition. I’m going to try recreating the image, as I think it should keep the playbook more applicable in different situations.
RSS Reader bug
A security update came across for PostgreSQL a few weeks back. After the upgrade I noticed the RSS reader wasn’t handling the disconnects as well as it should. Adding to the todo.
Books
We finally got through The Five Dysfunctions of a Team at work. So obvious, so meaningful. Definitely helpful in reminding us teams are more than a collection of people. The follow up book, Overcoming the Five Dysfunctions of a Team wasn’t worth it for me at this juncture. It’s funny, some people were really annoyed by the fable format. I loved the casual nuances that it brought to the subject at hand.
I’m most of the way through Scaling up excellence. In pursuit of a sparing partner for this one, as the team isn’t ready yet. It’s good material, but for some reason, it wasn’t sitting right with me. As it’s wrapping up I think I’m warming up to it more.
More on both later.
The Future
- My commentary on the whole CentOS + Red Hat deal (Yes, I know I’m late!).
- I got pulled into another project that I’m using my Eucalyptus cluster for. Google’s Wikipedia links an easy dataset to get started with. It turns out that the Eucalyptus disk subsytem is slower than I thought. I’ll need to do a benchmark on it. More on this later.
The Journey
A week ago was another Agile and Beyond conference. Even though we had some excellent talks such as Joshua Kerievsky TechSaftey keynote, it wasn’t as impactful as years past. To be fair, I had seen Joshua’s talk last year at the Lean Kanban conference. I’m glad it wasn’t as impactful; I think it means I’m starting to gain a more foundational understanding of things. It is funny, my first time at the conference it wasn’t about being impactful, it was about being relevant. But let’s start at the beginning.
I’ve always been drawn to people that have mastered their craft. The insights you could draw from their work seemed more meaningful. Their bravado given off when talking about their domain charmed me. When I graduated college and set off on my programing career full time, I fully intended to master my domain. My opportunities landed me at company that was rapidly growing, and an environment where I could grow along with it. Looking back, my folly was not realizing I was devoid of a mentor, and doing what I needed to do to seek one out. I soon found the addictive grove of “getting things done”, with a waining regards to mastery of my craft. In the back of my mind it bothered me. As years passed, responsibilities grew, my time spent on my craft got thinner and thinner. The backlog grew and grew, and I needed help. There were always people around willing to lend a helping hand, but I needed more. Someone with more insights than casually looking at problems. In part it was my craving to get back to my craft, in part it did seem like without professional help, the backlog would never be tamed. A long story short, I learned lessons about interviewing, and putting together a team. We hired, and we grew.
Ignorance is bliss. Except that it wasn’t. Now that there is a team, there needs to be direction, coordination, and organization. I didn’t see it coming, and I didn’t embrace that I needed to master a new domain. Again after a while the mastery craving kicked in, and I found a local and cheap conference to go to. Not having a mentor to help push me when I needed it, or a work environment that strived for continuous improvement, this was long overdue. I found myself at my first agile conference, Agile and Beyond. In part I loved it because I was immersed with people that were trying to perfect their craft. In part, I hated it because I still viewed myself as a developer and I didn’t have a true understanding of the Agile Manifesto. It was another way to “get stuff done”, but there didn’t seem to be a way to for a developer to master their craft. When you work on a library, you just worked on the parts you needed. Your frameworks where always going to be half done. Your work driven by what the customer wanted, and not what you know needed to be done. It was naive and frankly a little embarrassing that those thoughts are not farther in my review mirror. Even as off kilter as I was, my agile mastery had begun.
Back to current day. The conference wasn’t as impactful to me, but it was a good experience, and I was happy to be continuing to learn. What’s finally starting to sink in is that if I’m reaching for mastery, I will certainly be a lot closer if I’m incorporating others feedback. Agile and Lean certainly strive to do just that. You start to realize that others can help you validate your ideas. Others can help you with things that you would have never thought of. Intelligence will get you far, but being humble, understanding other peoples perspectives, and using their intelligence will get you farther. It’s not that I ever viewed feedback with disdain, but it’s certain that I didn’t interpret it appropriately. I keep coming back to thinking about that code library that you want to perfect. You plan things out, but eventually run into a problem. How many times after pulling out your profiling tools did you refactor code where you thought you would have to refactor. Feedback from your tests, from your profiling, from your crash reports, and feedback from your users. They all drive that well crafted library. So when you work on your library, there is less to refactor, and less to debug. You have just what you need. You end up listening to the users of your framework, and it becomes complete in their eyes. What you work on rarely feels wasted.
So that’s my journey so far. One traveled by many people wanting to perfect their craft. Feedback and mastery are more intertwined then what you naively think in the beginning. Be mindful of what you should be mastering. Have a mentor. Their feedback will be good, and their help with navigating other feedback will be beneficial. Nothing is ever finished. Just like the journey.
P.S. My twitter feed is a pseudo-mentor right?
Micro Cloud
A 3 node cluster for under $1000.
I have a few projects that I wanted to work on that would be easier if I had multiple machines for. One project was getting Eucalyptus up and running, and that required physical machines. I also have space constraints, so picking up some old servers on ebay wasn’t an option. So I needed something relatively new that had hardware virtualization support, enough RAM to run VM’s, and something cheap enough that I wasn’t breaking the budget.
| Part | Quantity | Price | Total Price |
|---|---|---|---|
| Acer Veriton Nettop Computer - Intel Celeron 887 1.50 GHz - Gray, Black | 3 | 222.99 | 668.97 |
| NETGEAR 8 Port Gigabit Smart Switch - Lifetime Warranty (GS108T) | 1 | 79.99 | 79.99 |
| Crucial 8GB (2 x 4GB) 204-Pin DDR3 SO-DIMM DDR3 1600 | 2 | 89.99 | 179.98 |
| Total | 928.94 |
The little nettop’s are great. Small enough for a couple of them to sit on my desk with out looking overwhelming, quiet, low powered, and easy to upgrade the memory and disk (also includes a mSATA slot). I also picked them up on sale for $180 each, which made it even a better deal. The switch is necessary because I would like to do a “Managed” network setup with Eucalyptus and I need VLAN support. It’s is limited to 64 VLAN’s, but that will be plenty for this setup.
- Install the switch, connecting it to my home router.
- Install the RAM, run memtest.
- 8GB in the first node, and split the memory for the other nodes so they have 6GB each.
- Install CentOS, getting rid of that awful Linpus distro.
- Creating an USB netboot was the easiest thing for me.
- Prep the network
- Configure the router.
- Shorten the DHCP Range to give a few IP’s for our new “public” range.
- I’m using the routers MAC->IP assignment in DHCP to set some “static” IP’s for the switch, and nodes.
- Configure the switch
- Quite possibly one of the hardest steps since the web interface is so painful.
- Go to Switching -> VLAN and add VLAN’s 10-13
- Verify that VLAN 1 is set to untagged for all of the ports.
- Go through VLAN 10 through 13 and set them to “T” for tagged on all of the ports. (Yes, the little triangle is overly difficult to toggle to show the ports).
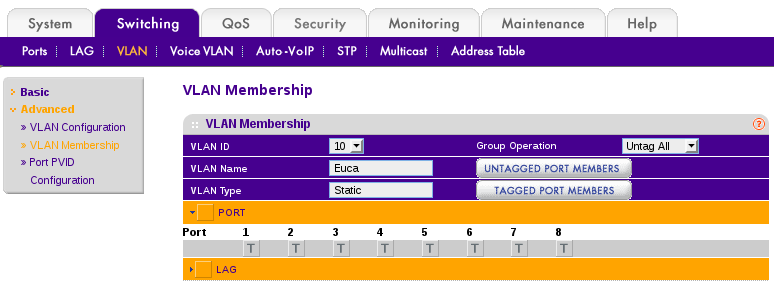
- Configure the router.
- Install Eucalyptus
- For the most part, just follow the directions.
- Put your CLC, CC, SC, and Walrus on the first node with the most ram.
- Make sure you let Eucalyptus know which VLAN’s it can use
euca-modify-property -p cloud.network.global_min_network=10 euca-modify-property -p cloud.network.global_max_network=13
- The IP’s that you took away from your router’s DHCP range. Add them to your config:
VNET_PUBLICIPS="192.168.1.240-192.168.1.250"
- For the most part, just follow the directions.
A couple of issues needed to be dealt with before I was ready to go.
- I do not run a DNS server on my local network.
- I got tripped up using euca2ools until I figured out there were a bunch of subdomains that it was looking for. I simply added hosts to /etc/hosts on my workstation. I’ll need to do this on any workstation I’m using euca2ools from, or get around to setting up a local dns server.
192.168.1.210 node1 eucalyptus.cluster.<domain> walrus.cluster.<domain> euare.cluster.<domain> tokens.cluster.<domain> autoscaling.cluster.<domain> cloudwatch.cluster.<domain> loadbalancing.cluster.<domain> 192.168.1.211 node2 192.168.1.212 node3
- I got tripped up using euca2ools until I figured out there were a bunch of subdomains that it was looking for. I simply added hosts to /etc/hosts on my workstation. I’ll need to do this on any workstation I’m using euca2ools from, or get around to setting up a local dns server.
- I do not run an email server on my local network.
- The cloud controller likes to send you emails to register accounts. You can probably get around this, but I have an email server on my colo, I figured this wouldn’t be to bad to get going.
- For the most part it was pretty simple. I use self-signed certs on my mail server, and it took my a while to figure out I needed to remove the “noplaintext” option from smtp_sasl_security_options, even though it wasn’t being transported over plain text.
- I created a user on my email server.
- I put the credentials in /etc/postfix/relay_auth on node1 (see docs for smtp_sasl_password_maps for syntax)
- I configured the mail server (postfix) to relay to my server, and use sasl_auth.
relayhost = [mail.example.com]:submission smtp_sasl_auth_enable = yes smtp_sasl_password_maps = hash:/etc/postfix/relay_auth smtp_use_tls = yes smtp_tls_security_level = may smtp_sasl_security_options = noanonymous - I believe with newer versions of postfix, you might be able to whitelist the self-signed cert, and can make sure your TLS settings are a little tighter.
- The cloud controller likes to send you emails to register accounts. You can probably get around this, but I have an email server on my colo, I figured this wouldn’t be to bad to get going.
euca2ools was out of date on my distribution.
- I was running into a strange problem trying to create images from my workstation using euca2ools (from eustore). I was getting this error message:
InvalidAMIName.Malformed: AMI names must be between 3 and 128 characters long, and may contain letters, numbers, '(', ')', '.', '-', '/' and '_'
A little digging, and I realized my euca2ools was version 2.x and it was 3.x on all my nodes (where I successfully imported my first image from eustore). A quick upgrade to the latest version, adjusting my path, and I was importing and uploading my images.
- I was running into a strange problem trying to create images from my workstation using euca2ools (from eustore). I was getting this error message:
It booted! Wait.. where did it go?
I successfully booted my first instance, and everything worked! I SSH'ed into my virtualized CentOS 6.4 instance via the “public” IP 192.168.1.240. I verified that it had a 10.101.x.x IP on the backend, and was using a VLAN. So, things are working, let’s get this instance up to date. “yum upgrade” got me to 6.5, I rebooted an suddenly found I could no longer reach the instance. For some reason, I’ve always thought it was going to be the networking that was the hardest part in all of this, and I jumped to the conclusion that it had failed me. The instance was still up on my node after all. Long story short, after spending waaay too much time on iptable LOG insertions, I realized that this was actually something on the instance. I destroyed it, and started again. This time I paid closer attention, and found some SELinux errors after the upgrade (but before the reboot!). I haven’t found exactly what is wrong, but a “restorecon -Rv /” fixed things for now so that it survives a reboot.
Next steps
Right now to launch an instance it’s a simple:
1
| |
I need to learn a little bit more about the security groups to really get going though, as I’m sure I’ll need something other than port 22. Once I figure that out, it’s off to Ansible, to see if I can deploy my RSS app automatically.
Happy clouding!
